US President Donald Trump has announced 10% tariffs on all imports into the US, with some countries facing higher rates, sparking global trade concerns and market falls. World leaders warn of a potential trade war and recession.
Tom Howard is joining HN moderation, replacing the previous moderator, and will post as tomhow. He has been a long-time HN user and YC participant, sharing his startup experiences and learning from others.
Inspired by the Twitter logo, which is made from 13 perfect circles, I decided to give myself a design challenge. I haven't done aesthetic work in a while and I wanted to show something simple & nice in my portfolio! So, here are 13 animals each made out of 13 circles!
We provide services for rapid web prototyping, allowing developers to share projects easily without installations. Our services use existing SSH tools to publish content and send daily email updates.
The user avoids discussing politics with friends due to the prevalence of tribalism and the desire to maintain relationships over truth. They believe that seeking truth and understanding requires a willingness to question one's own biases and engage in nuanced, probabilistic thinking.
Age LAN Server allows offline multiplayer LAN game modes for Age of Empires games without an internet connection. It requires a custom launcher and admin rights to run, and supports Windows versions of Age of Empires: Definitive Edition, II, and III.
Mozilla is expanding Thunderbird into a full communications platform with Thundermail and Thunderbird Pro, competing with Gmail and Microsoft 365. The platform will offer features like scheduling, AI-powered writing, and email hosting with open-source values of privacy and transparency.
Coolify is a versatile platform for deploying and managing applications across various servers and frameworks. It offers features like automated SSL setup, real-time terminal access, and customizable integrations for streamlined development and teamwork.
30 years later, real genius still holds up better than most college films. the film doesn't showcase as many women as we might hope for, but the way it treats the majority of those women is impressive. real genius occupies an interesting middle ground in how it portrays education for a film that's about brainy, bookish people - elizabeth taylor-mccarthy argues nerds have
Color is disappearing from our world due to a historical bias against color in Western philosophy. This bias has led to a preference for grayscale and neutral tones in design, branding, and art.
NSC officials used Signal for national security chats, potentially violating regulations on sensitive information and recordkeeping laws. Officials claim they used Signal for unclassified material, but some details shared were likely classified.
The author argues that people are not bad at their jobs, but rather the jobs themselves are bad due to poor working conditions and low pay. This leads to a culture of accepting cheap, low-quality products and services, which ultimately costs us more in time and frustration.
Automattic is restructuring to improve productivity, profitability, and capacity to invest, resulting in a 16% workforce reduction. Affected employees will receive financial and support benefits, and the company will communicate clearly and compassionately throughout the process.
MIT's Secure Hardware Design Class teaches students to attack and defend modern CPUs through hands-on experience and state-of-the-art hardware attacks and defenses. The course includes labs, lectures, and recitations that guide critical thinking and engagement with research literature on hardware security.
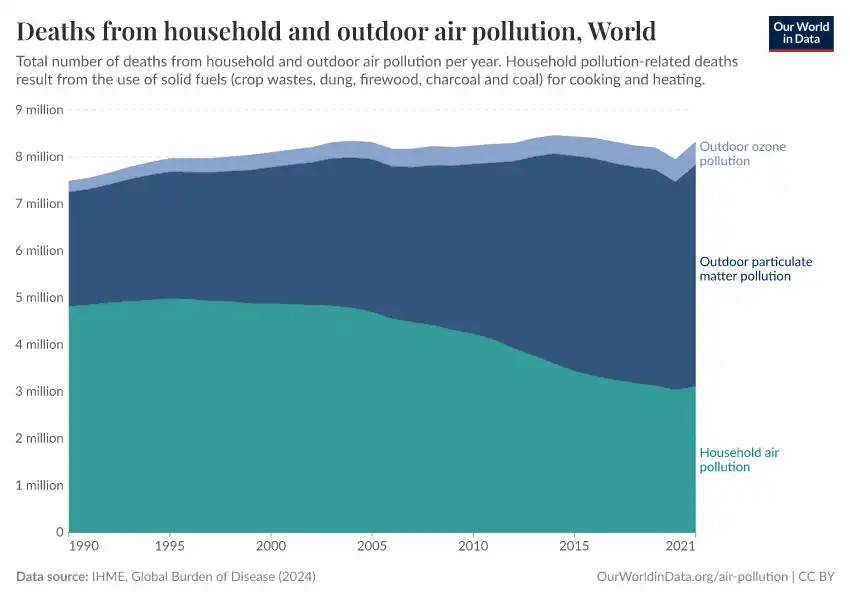
Air pollution kills millions every year, mainly due to human activities such as burning fossil fuels and biomass. The Community Emissions Data System (CEDS) provides valuable data on global emissions, helping to understand where air pollution comes from.
The Internet Archive's Wayback Machine preserves government websites and datasets, crucial for scientific research and reproducibility. Digital preservationists like archivists at the Internet Archive and Harvard Law School ensure the integrity of the scholarly record by safeguarding public access to information.
Google DeepMind's Gemini 2.0 models enable robots to perform complex tasks without training, using multimodal outputs like text, video, and audio. The Gemini Robotics model allows robots to react to new objects, environments, and instructions without further training, making them highly dextrous and interactive.
Matrix.org will migrate to MAS on April 7th, 2025, for next-generation authentication with improved security and registration experience. This change brings a new account management interface and supports next-generation clients without breaking compatibility with existing APIs.
Supervisors often reward rule breakers, especially if they think it helps the team. However, this can lead to a culture where rule breaking is encouraged and hurts the team in the long run.
The user encountered a mysterious error while running yarn test on their React project, which was caused by a naming clash between Jest's sl command and a Steam Locomotive program named sl. The issue was resolved by renaming the Steam Locomotive program, and further investigation revealed that Jest was running the sl command 4 times to cover 16 root directories, resulting in a timeout after 27 seconds.
Aaron Davis, a coffee researcher, created a "Wanted" poster for the rare coffee plant Stenophylla, which was last seen in the wild in 1954. He finally found the plant in Sierra Leone's forests in 2018 and discovered it has a superior taste to other coffee species.
A historian reflects on a 1970 conversation between Jorge Luis Borges and Herbert A. Simon, discussing free will and determinism in the context of AI and machine learning. The conversation highlights the intersection of humanities and STEM fields, a theme the historian believes is essential for future research and innovation.
New research shows creatine supplements do not help people build muscle faster when lifting weights. A 12-week trial found both creatine users and non-users gained two kilograms of lean body mass.
A security vulnerability was found in the Verizon Call Filter iOS app, allowing attackers to access call history logs of Verizon Wireless customers without their consent. This issue was caused by a server not validating user phone numbers, potentially putting journalists, police officers, and abuse survivors at risk of surveillance.
Researchers propose Multi-Token Attention (MTA) to improve LLMs by considering multiple query and key vectors. MTA achieves enhanced performance on language modeling tasks and searching within long contexts.
Modules have many uses, but they are often mixed up. >i'd like to have module renaming/namespacing! - specifically, i want to clean up the naming&mistakes inthe stdlib without affecting old programs. as systems get very large the notion of files andmodules seems to break down, to be replaced by'search-able stuff in
Cnn's richard quest set out on his first solo cruise in a 19-foot potter 19. he ran two additional jacklines to secure cargo and brought fresh food - 320 pounds! quest found that despite being designed for cruising, the boat behaved quite well in the open ocean and the trade winds. quest also got to see the particular style of anchoring and stern tie that is used at the 10'
The Mermaid Chart VS Code Plugin integrates Mermaid.js diagramming into VS Code for seamless workflow and collaboration. It offers real-time editing, syntax highlighting, and cloud sync features for team collaboration and large projects.
Scientists have observed the gravitational deflection of starlight and distant galaxies, including Einstein Rings, which are circular distortions of light caused by perfectly aligned galaxies. The James Webb Space Telescope recently captured a beautiful example of an Einstein Ring, showcasing the power of modern telescopes in observing distant celestial objects.
Nintendo Switch 2 is coming June 5, 2025, with a $449 base price and $499 bundle with Mario Kart World. It features improved visuals, a new C button for chat, and mouse controls for games like Drag x Drive.
Yann lecun is a turing award-winning artificial intelligence pioneer. he believes that large language models will be obsolete within five years. his innovations at bell labs led to practical applications that quietly revolutionized everyday systems. the future of ai is where systems form 'interactive societies of machines.& #34; - lecun. anthropic.com., jan. 8 – p.m. est.
PaperBench is a benchmark evaluating AI agents' ability to replicate state-of-the-art AI research by replicating 20 ICML 2024 papers from scratch. The best-performing agent, Claude 3.5 Sonnet, achieved an average replication score of 21.0%.
To create an adaptive simulated economy, we need to think at the level of the individual and model how people make economic decisions. We start with a simple decision-making algorithm where individuals track two numbers: their personal value of a good and their expected market value. This allows us to determine if they are a buyer or seller. We then simulate a market with 200 actors, each ...
When crossing a boarder, assume the following will happen (actually rarely unless you are an poi) to wipe your android phone “safely” check whether encryption is activated. avoid taking food and other bio hazards through customs, as that may also draw attention. the reason we don’t “de-frag” drives these days is that they are mostly all “journaling file systems” and this causes all sorts of ...
The user discusses AI agents and proposes a definition based on identity, where an agent is a system that takes independent actions under its own identity. This definition implies autonomy, capability, and reasoning, distinguishing agents from assistants like copilots or in-product assistants.
Wikimedia saw a 50 percent increase in bandwidth due to AI crawlers scraping content to train AI models. This traffic spike poses risks and costs, and Wikimedia is seeking sustainable ways to access its content.
Ace is a computer autopilot that performs tasks using mouse and keyboard, outperforming other models on various tasks. It's still learning and making mistakes, but will become more intelligent with increased training resources.
Researchers conducted a Turing test with 4 systems, finding GPT-4.5 passed 73% of the time, while LLaMa-3.1 passed 56% of the time. This is the first empirical evidence of an artificial system passing a standard Turing test.
You created a customizable pet extension for editors like VS Code, ideal for streaming or classroom use. The extension can also have interactive features like a "thinking" animation when the cursor is busy.
Rutgers University researchers captured 24-hour images of living plant cells building cell walls, providing insights for more robust plants and lower-cost biofuels. The study reveals a previously unseen process of cellulose synthesis and assembly in plant cells.
To live off OSS contributions, combine work with social media and participate in hackathons for monetary prizes, but be aware of the quality and marketing focus. Many OSS contributors are on company payrolls, and local government grants or convincing companies to contribute back to used libraries can also help cover costs.
Hardware accelerated raytracing relies on an abstract data structure, known as “acceleration structure” or “bls”. the driver is responsible for building shader code that iterates over the scene, using the special instructions for node tests. with fp32 box nodes, we estimate that bvh can take a minimum of 114 bytes/triangle on amd hardware; the largest number we can see from the official driver
Ekeoma uzogara estimates effect of driver race on citations and fines for speeding. he says analysis of full extent of racial profiling would find evidence for targeting statistical discrimination too. findings suggest that police racially profile drivers due to police having animus or prejudice, says author. study was conducted on active lyft drivers in florida during 2017 to 2020 - mrue.
A vulnerability in Microchip's SAM4C32 microcontroller allows an attacker to gain unlocked JTAG access by exploiting a voltage glitch on the reset pin. This attack affects many SAM family devices that use GPNVM bits for security.
We deployed 100 RL-controlled cars to smooth highway congestion and reduce fuel consumption by learning to maximize energy efficiency while maintaining throughput and safety. The experiment resulted in 15-20% energy savings around controlled cars.
Cache effects can have a significant impact on Python code performance, especially for large problem sizes, and can be optimized by using cache-friendly data structures and access patterns. The author of the post conducted experiments using Python and the numpy module to demonstrate the impact of cache effects on performance and provided suggestions for further optimization and resources for ...
A documentation site is being created to recreate and update the Work Simplification program, a 1940s-1960s government efficiency tool. The goal is to make process improvement accessible to local groups and civic organizations, focusing on effectiveness and citizen experience.
Vibe coding is a trend that's harmful to startups due to increased tech debt and money loss. It's better to hire experienced engineers who can use AI effectively, rather than relying on vibe coders with little experience.
Sparks is a webfont that uses OpenType's contextual alternates feature to create sparklines. It works on modern browsers and has three variations: bars, dots, and dot-lines, each with five weight variants.
Data General's ambitious project to create the Eagle computer was a story of innovation, teamwork, and perseverance. Tracy Kidder's book "The Soul of a New Machine" tells the story of this project and its impact on the minicomputer industry.
SSLyze is a tool that scans servers for strong encryption settings and known TLS vulnerabilities. It's a reliable, battle-tested tool that can be easily integrated into CI/CD pipelines and supports various server types.
A new CSS layout system called Item Flow is being proposed to unify Flexbox and Grid properties. It would include four new properties: item-direction, item-wrap, item-pack, and item-slack.
Install apps on phone to use ebook as GPS, requires Kickweb server and BlueNMEA apps. Modify index.php file to add features or change units, use Google and comments for guidance.
A developer shares a story about the evolution of a software application's configuration, from hard-coding values to implementing a business rules engine and a DSL. The story highlights the increasing complexity and potential drawbacks of overly complex configurations.
Multi-threaded programming in rust works well because of the send and sync traits. condition variables seem hugely underused, but i’ve not yet found a need for them - despite the fact that they can be used to synchronise threads' reads and writes to the shared heap are not always reliable if they aren't backed up logically by atomic_signal_fence and the like
Didion: a lot of psychiatrists are attracted to the specialty because they themselves are depressed. she says the freight for her was not the cancer, but it may have been the isolation. the book is about coping with the world, not about how to deal with it, she writes - and how we can change it for the better if we do it right. douglas brinkley, who wrote the novel, says we need to be more
Chronic ethanol exposure alters striatal plasticity during value-based decision-making. dynaprl task shows sex-dependent changes in encoding of reward learning signals - etoh males more likely to repeat choice if reward is halved or doubled in the current trial, compared to control group, says daniel schmidt, who co-authored the study with jennifer
The Holepunch team has launched Bare, a minimal JavaScript runtime for desktop and mobile with a focus on modularity, universality, and scalability. Bare enables developers to write secure, lightweight, and efficient peer-to-peer applications that can run on a wide selection of hardware.
Cyrus Reed Teed's cult Koreshanity believed in a hollow Earth, an idea first proposed by Edmond Halley in 1692. Halley's theory, though wrong, was well-reasoned and laid the groundwork for later scientific discoveries about Earth's layers.
Joanne Chew found deepfakes of herself online after a big accomplishment, with racist slurs and titles, and was harassed by a user named Ron who created over 2,000 pieces of content. She enlisted help to report and remove the content, but the harasser continued to post new content and even contacted her directly.
Minecraft is a popular video game that taps into children's innate desire to build and create, allowing them to express themselves and develop skills. Experts say the game's broad appeal and versatility make it an ideal platform for children to learn and socialize.
The author argues that presentational attributes like bold and italic text are essential for clarity and expressiveness in electronic text. He criticizes the way these attributes are stored on computers, which pollutes text streams with non-text information.
This repository is a simplified implementation of denoising diffusion in PyTorch, refactored from The Annotated Diffusion and Phil Wang's repository for easier understanding. It includes functions and classes for forward and backward diffusion, data handling, and model training.
The user argues that multithreading is inefficient and introduces complexity, and that isolating problems with single-threaded code is a better approach for optimal CPU-time usage. This design, as seen in Node.js, allows for easier deployment and writing of code, and is more efficient than multithreading, which can lead to complex bugs and poor CPU-time usage.
Val Kilmer, actor known for Top Gun and Batman Forever, has died at 65 due to pneumonia. He was a talented actor who struggled with throat cancer and had a complex career with both successes and controversies.
Combining LLMs with Prolog combinatorial search is a natural fit for automated planning, leveraging LLMs' language abilities and Prolog's combinatorial power. This approach complements LLMs' strengths in language tasks with Prolog's logical underpinnings.
A stateless traveler guide advises visiting the embassy in person, finding a visa through a business contact, and dressing properly for immigration. It also suggests choosing the right officer, explaining statelessness, and staying polite to increase chances of a smooth passage.
To securely communicate over the internet, a shared secret key is generated using Diffie-Hellman Key Exchange, but this only prevents message reading, not tampering. To ensure authenticity, a trusted third-party (Root) signs the website's public key and name, creating a Certificate that forms a centralized trust system known as Public Key Infrastructure (PKI).
Croatian director Igor Bezinović's film "Fiume o Morte!" reenacts a tumultuous period in his hometown of Rijeka. The film combines nonfiction elements with fictionalizations of historical events, emphasizing the director's personal connection to the saga.
BuzzBench is a performance testing tool that provides comprehensive testing from CLI to dashboard. It offers distributed testing with lightweight agents for accurate metrics from actual infrastructure.
The town of Lyss near Bern has a unique traffic circle called the KUFA Kreisel, featuring a 12-meter diameter record player with 800 silver metal washers. It was designed by the creative folks at KUFA and has become a viral attraction near a popular cultural venue.
Heroku now supports .NET, offering a cross-platform ecosystem for developers. .NET applications on Heroku are fully supported in production environments with robust infrastructure and support services.
The US government is enforcing Real ID, a federal guideline for state driver's licenses, which requires more documents and could lead to identity theft and discrimination. Americans should refuse to get Real IDs and instead opt out to create pressure on the government to repeal the rule.
Transformer-based llms have no ability to explicitly access their own internal states. rewind the model to any past internal state and explore alternative continuations. this represents a paradigm shift from machine learning to "machine self-improvement through reflective latent simulation. the transformers are based on naive feed-forward networks, but future iterations could explore ...
If you were 18 in 2016, I'd recommend learning to code, building an online business, and living cheaply to achieve financial freedom. Focus on experiences, relationships, and personal growth over material possessions.
PowerToys Command Palette is a customizable tool that allows fast access to frequently used commands and apps via Win+Alt+Space. It can be customized and extended with favorite apps, and settings can be accessed within the tool itself.
The Functor typeclass in Haskell represents any type that can be mapped over, allowing functions to be applied to values within a wrapped context. The fmap function, part of the Functor typeclass, applies a function to a value within a functorial context, enabling clean and expressive code in functional programming.
Outlawing advertising would remove mechanisms for personalized manipulation and force politicians to snap back into reality. This would be a liberating act, allowing people to think critically and break free from addictive digital content.