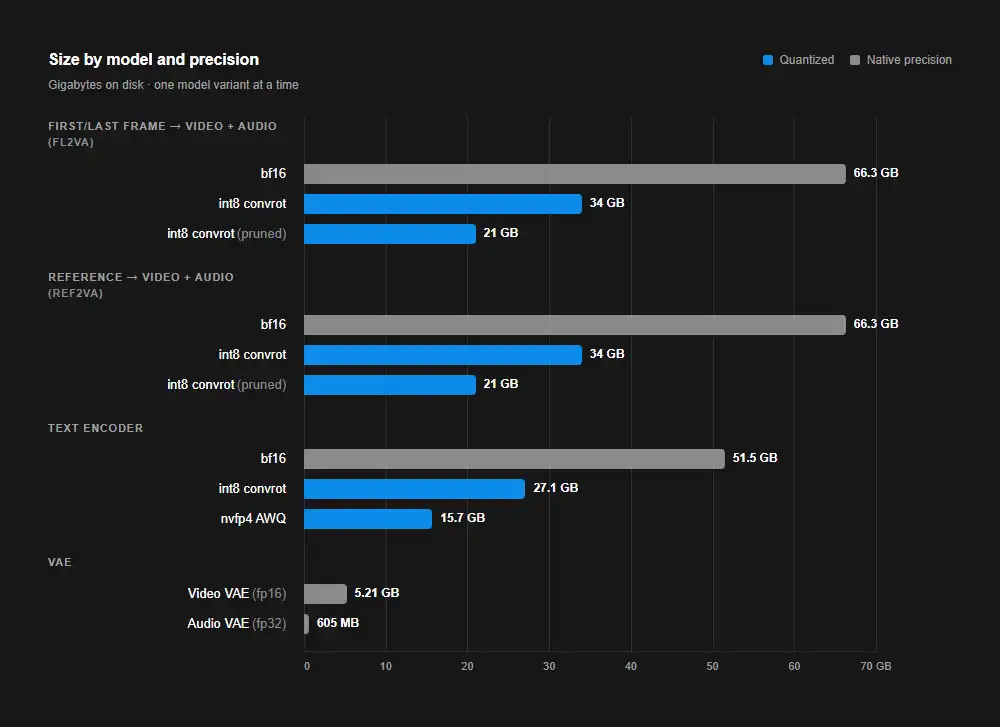
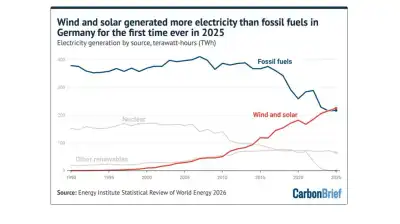
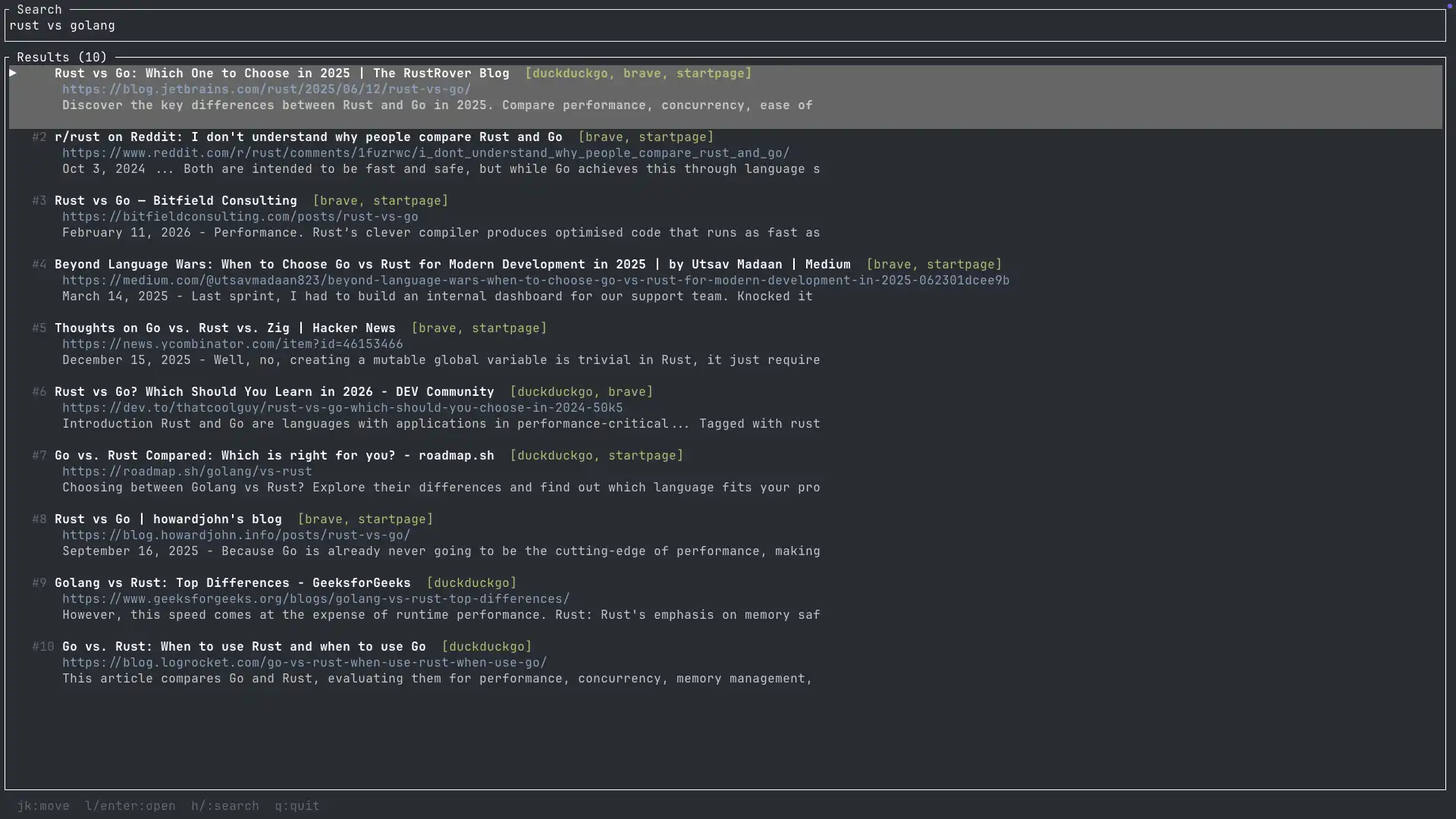
Software engineers used to rarely write personal software, but now agents can easily manage customizing software, making it easier to personalize and maintain. Agents can build and manage custom software with minimal programming, allowing for more efficient and flexible use of software.