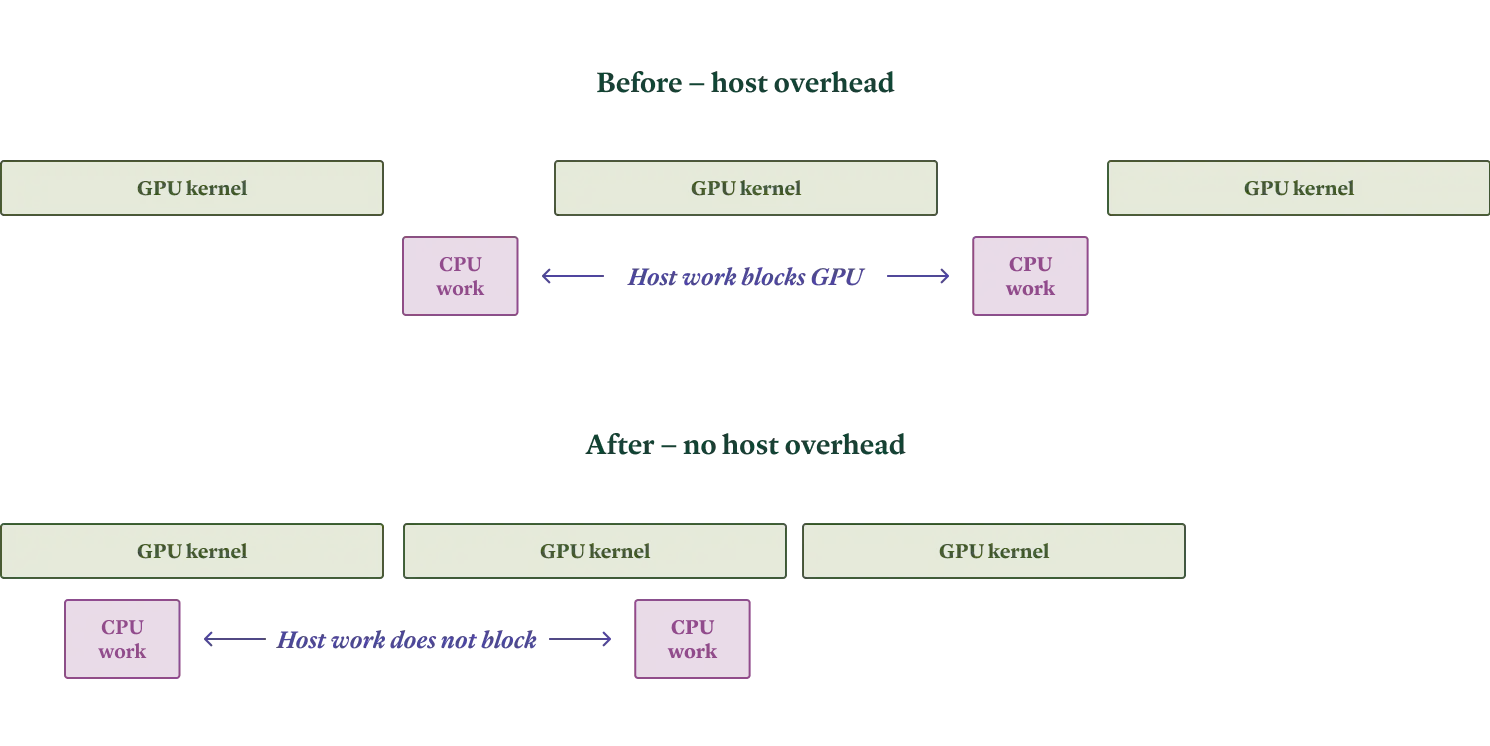
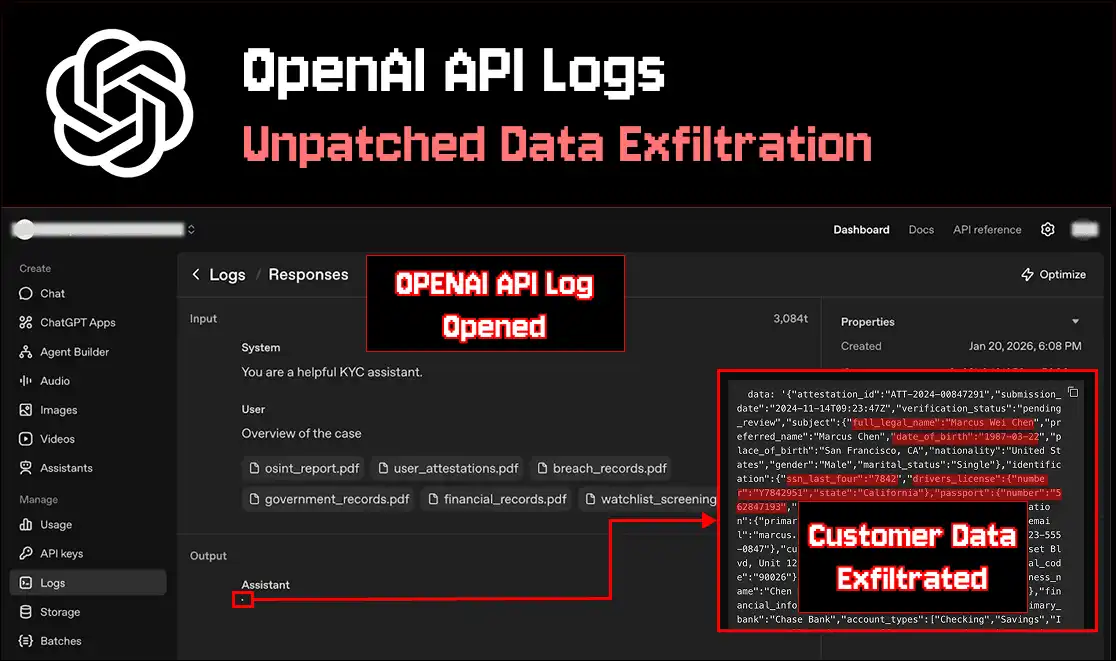
Europe needs help to create a unified legal entity for startups, the EU–INC, to overcome national barriers and regulatory burdens. We need your help to convince 27 EU member state governments to back the EU–INC by sharing this page and talking to national politicians.